Abstract
Background and Purpose: Cardiovascular disease (CVD) is a leading cause of death and disability in the world. Many CVD risk prediction models have been created, but those most widely used in clinical settings have not been externally validated, a significant gap addressed herein.
Methods: Using the Multi-Ethnic Study of Atherosclerosis (MESA), we have externally validated the Framingham Risk Score, ASSIGN (Assessing the cardiovascular disease risk using SIGN) risk score, Atherosclerotic Cardiovascular Disease (ASCVD) risk score, and the European SCORE model, which were selected based on popularity among clinicians and frequency of clinical use. The models were implemented in a computer program based on published algorithms, and 100 incident CVD and 100 non-incident CVD subjects from MESA were selected for testing the repeatability. The outcome in both models achieved 100% correlation. The individual model accuracy was tested by computing their sensitivity, specificity, accuracy, and C-statistics.
Results: For discrimination, ASCVD showed the highest C-statistic (0.717) and SCORE the lowest (0.677). The Framingham score provided the most consistent results among the models, with a sensitivity of 69% and a specificity of 62%, but overestimated the risks as shown by the calibration results. SCORE was relatively inconsistent, with a sensitivity of 34% and specificity of 85%, for a risk threshold set at the top 20%.
Conclusions: Calibration experiments showed that the transportability of the risk was generally poor in all models, with Framingham and SCORE particularly overestimating the risks for the American population There is clearly a need for better models to predict CVD risk in the multi-ethnic American population.
Keywords
Cardiac biomarkers, Cardiovascular risk reduction, Congestive heart failure
Introduction
Cardiovascular diseases (CVDs) such as heart disease, stroke, etc. are the most deadly health issues in the world [1-3] producing a huge financial burden on societies [4-6]. Predicting the risk of CVD is essential for optimizing management and treatment guidelines. Extensive research has been conducted to develop prediction CVD models [7-9], yet their validity is a cause of concern.
The current standard of care for CVD prevention is based on risk prediction models with multiple risk factors such as age, gender, hypertension, dyslipidemia, smoking, etc. There are well-known models such as the Framingham Risk Score [10], the Prospective Cardiovascular Münster (PROCAM) score [11], the Dundee risk disk [12], the British Regional Heart Study [13,14], Korean heart study [15], SCORE [16] and the QRISK3 prediction model [17]. However, many of the risk scores used in clinics are either developed locally or are non-local models calibrated to suit the local population [18] and determine preventative measures [19]. These models have been adopted in primary care settings as simplified charts, tables, computer programs, and web-based tools, and are routinely referred to in policy documents and guidelines.
These models do not capture all cardiovascular risks: the Framingham risk score is superior to any single risk factor or model but can only predict up to 50% of CVD cases. Also, recent systematic reviews [16,20] reported that the Framingham risk score has a variable performance with under-prediction and over–prediction of the risk in high-risk and lower-risk populations, respectively. Risk overestimation causes increased costs, and risk underestimation leads to missing vulnerable cases.
Our literature review-based observations suggest many reasons that have led to a lack of reliable applied prediction models for heart disease: i) no comprehensive overview of the models has been undertaken, ii) only a few were externally validated on their predictive performance, and iii) lack of external validation makes them almost valueless for practitioners, policymakers, and guideline developers. Therefore, despite many studies [21-23] on these models, the critical element of external validation to assess performance when transported to other regions has been lacking. In this paper, we validate four major CVD risk prediction models externally on the MESA dataset.
Methodology
Selection of prediction models for external validation
We used a published review on the latest use of prediction models for cardiovascular disease and how to choose the right one [18]. The selected models are among the most promising and are implemented practically in clinical settings. In addition, we used the model mentioned in the American Heart Association and the American Cardiovascular Association (AHA/ACA) guidelines [24]. In total, four CVD risk prediction models are used in this study.
Prediction models included for analysis
The various CVD risk prediction models that are selected are briefly described below. The common practice for building models is to use Cox proportional-hazards regression to form an equation that outputs the risk percentage. It is, sometimes, further simplified by making it a points-based scoring system that is easy for clinical use. In brief, the natural logs of the predictors (age, total cholesterol, HDL cholesterol, Systolic BP, etc.) are calculated. These values are then multiplied by the coefficients from the equation (usually for the specific race-gender group of the individual). The sum of these products for all factors is calculated. The estimated 10-year risk of a first hard ASCVD event is formally calculated as 1 minus the survival rate at ten years raised to the power of the exponent of the sum minus the race- and sex-specific overall mean sum. This general method is used to calculate the risks in most models.

Where S is the baseline survival, IndX’B is the coefficient X value, and MeanX’B is the overall mean of race-specific and sex-specific coefficient X value.
Framingham risk score for cardiovascular disease (FRS-CVD)
Framingham risk scores were originally developed on the data obtained from the Framingham Heart Study to estimate the 10-year risk of developing coronary heart disease, with additional risk scores for other cardiovascular diseases and events developed later [25]. In our study, we use the Framingham scores for 10-year cardiovascular disease risk [26]. The Framingham CVD risk score is a gender-specific Cox proportional-hazards regression based on age (30-74), total cholesterol (100-405 mg/dL), cigarette smoking status, HDL cholesterol (10-100 mg/dL) and systolic blood pressure (90-200 mmHg) to estimate the risk of an event in 8491 Framingham study participants between the ages 30 and 74 and free of CVD at recruitment. The point-based system to calculate the risk score is outlined in Appendices 1 and 2 for women and men.
ASSIGN risk score
The ASSIGN risk score [27] was developed on the data and cardiovascular outcomes in the Scottish Heart Health Extended Cohort (SHHEC) [28] to assess the 10-year percentage risk of cardiovascular disease (any manifestation of coronary heart disease or cerebrovascular disease including transient ischemic attacks). Participants were 6,540 men and 6,757 women aged 30-74, initially free of cardiovascular disease, ranked for social deprivation by postcode. The unique aspect of the ASSIGN score is the addition of social deprivation and family history to traditional risk factors found in the Framingham Score. It was shown to be marginally better in discriminating cases and non-cases than the Framingham Score [18]. The study provides mean scores for the components when the data is insufficient to produce a risk score. Since the MESA study does not have a social deprivation factor known as the Scottish Index of Multiple Deprivation (SIMD), we use 20 instead, suggested as the median value for SIMD by ASSIGN. The components in the model are age (25-90), sex, Scottish postcode for SIMD (or a median score of 20 for non-Scottish population), family history of CHD/Stroke, diabetes status, cigarettes smoked daily (0-100), systolic blood pressure (80-250 mmHg), total cholesterol (2-12.5 mmol/l), and HDL cholesterol (0.3 – 3.5 mmol/l).
Table 1 shows the published results based on the respective datasets used in the four risk prediction models within the performance measured by sensitivity, specificity, accuracy, and C-statistic. The top quintile is chosen for analyzing the performance measures, and for SCORE, a threshold of the top 5% (in low-risk regions of Europe) or above is shown. SCORE did not report top quintile performance in its original paper. The values are averages across population groups, and/or gender. The Framingham score is an average for four individual diseases (coronary heart disease, stroke, congestive heart failure, and intermittent claudication).
|
Study |
Population |
Incident CVD |
Sensitivity at High Risk (Top 20%/5% risk group) |
Specificity at High Risk (Top 20%) |
Accuracy at High Risk (top 20%) |
C-Statistics |
|
Framingham CVD |
8491 |
1174 |
66.46% (>20% risk) |
81.02% (>20% risk) |
NA |
0.733 to 0.851 |
|
ASCVD |
24626 |
2689 |
NA |
NA |
NA |
0.717 to 0.818 |
|
ASSIGN |
13297 |
1165 |
46.30% (>20% risk) |
82.50% (>20% risk) |
79.30% (>20% risk) |
0.727 to 0.765 |
|
SCORE (European CVD model) |
205178 |
7934 |
20-43% (> 5% risk) |
88-96% (>5% risk) |
NA |
0.74 to 0.84 |
ASCVD risk score
The atherosclerotic cardiovascular disease (ASCVD) risk score is based on the recommendations and guidelines provided by the 2013 American Heart Association (AHA) and American College of Cardiology (ACC) report [24]. A total of 11,240 white women, 9,098 white men, 2,641 African-American women, and 1,647 African-American men initially free of any fatal CVD were included. The components included in this risk calculation method are age (40-79), diabetes status, gender, race, smoking status, total cholesterol (mg/dL), HDL cholesterol (mg/dL), systolic blood pressure (mmHg), and treatment for hypertension. Gender- and race-specific equations were developed to predict the risk of the first ASCVD event. The formula for calculating the ASCVD score is provided by Goff et al. 2014 [24].
SCORE (European CVD risk score)
The SCORE project [29] created a risk-scoring system for clinical use among the European population. It combined data from 12 European cohort studies, collected patient data from 250,000 subjects, and recorded about 7,000 fatal CV events [30]. The score was developed differently for two regions of Europe, categorizing them as low-risk countries (predominantly Western Europe and Scandinavia) and high-risk countries (predominantly Eastern Europe). The model used age, gender, systolic blood pressure (mmHg), total cholesterol (mmol/L), and smoking status as inputs to the final percentage risk score. SCORE provides a simple and easy-to-use chart for reference and use in clinical practice. The procedure for calculating the risk percentage using the SCORE model is based on the European guidelines for CVD Prevention in Clinical Practice [31]. We used the low-risk version of SCORE to evaluate it on the MESA dataset because the MESA demographic (USA) matches the low-risk European countries as defined by SCORE.
The population of the external validation dataset
The Multi-Ethnic Study of Atherosclerosis (MESA) [32], with a primary objective of determining characteristics related to the progression of subclinical cardiovascular disease to clinical cardiovascular disease, is a research study of over 6,000 men and women from different ethnicities in the United States. The study is sponsored by the National Heart, Lung, and Blood Institute of the NIH. In the baseline was a diverse population sample of 6,814 men and women aged 45-84 without any known CVD conditions, but who could have risk factors. About 38% of the participants were white, 28% African American, 22% Hispanic, and 12% Asian. Females comprised 53% (3,601) of the study population, whereas males comprised 47% (3,213). Participants were followed for identification and characterization of cardiovascular disease events, including acute myocardial infarction and other forms of coronary heart disease (CHD), stroke, congestive heart failure, mortality, and cardiovascular disease interventions. The subjects had their first follow-up examinations over two years from July 2000 to July 2002, with a follow-up period of approximately 17-20 months, and were followed until their fifth exam before the dataset was made available. The fifth examination took place from April 2010 to January 2012. The baseline characteristics of the study participants who did/did not have incident CVD in the follow-up visits are shown in Table 2.
|
Baseline Characteristics of the Validation Cohort |
CVD (n=940) |
Non-CVD (n=5873) |
Missing data (%) |
|
Age, years ± SD |
68 ± 10 |
62 ± 10 |
0 |
|
Male, n (%) |
378 (40) |
2649 (45) |
0 |
|
Race/ethnicity |
0 |
||
|
Non-Hispanic white American |
380 (40%) |
2241 (38%) |
- |
|
Chinese American |
86 (9%) |
718 (12%) |
- |
|
African American |
260 (28%) |
1632 (29%) |
- |
|
Hispanic American |
214 (23%) |
1282 (21%) |
- |
|
SBP, mmHg ± SD |
136 ± 23 |
126 ± 22 |
0.3 |
|
DBP, mmHg ± SD |
74 ± 11 |
72 ± 11 |
0.3 |
|
Diabetes, n (%) |
357 (38%) |
2588 (44%) |
0.4 |
|
Current smoker, n (%) |
528 (56%) |
2846 (48%) |
0.3 |
|
Body mass index, kg/m2 ± SD |
28.72 ± 5 |
28.2 ± 6 |
0 |
|
Total cholesterol, mg/dL ± SD |
193 ± 33 |
194 ± 35 |
0.4 |
|
High-density lipoprotein cholesterol, mg/dL ± SD |
48 ± 14 |
51 ± 15 |
0.4 |
|
Low-density lipoprotein cholesterol, mg/dL ± SD |
117 ± 29 |
117 ± 32 |
0.4 |
|
‘n’ is the number of subjects, SD is the standard deviation, SBP is Systolic Blood Pressure, and DBP is Diastolic Blood Pressure. |
|||
Assessment of cardiovascular diseases
In the MESA study, the data regarding cardiovascular diseases were collected from a variety of sources, including death certificates, medical records, in-person interviews, autopsy reports, and actively contacting kin or doctor of the subject in case of death or occurrence of severe CVD. Fatal and non-fatal cardiovascular events are defined based on MESA criteria. Fatal events are further classified as definite fatal CHD, definite fatal MI, possible fatal CHD, stroke death, non-coronary/non-stroke death, and other cardiovascular disease death. Non-fatal events include MI, resuscitated cardiac arrest, angina, congestive heart failure, peripheral vascular disease, stroke, and TIA. In our study, we assess prediction models for overall CVD (fatal and non-fatal events) in the MESA dataset.
Assessment of predictors
The prediction models selected for this study use a variety of features/component variables for predicting CVD, such as socio-demographic data, medical history, family history, and social deprivation. Most of these parameters are readily available in the MESA dataset. The missing data were replaced by population means and by extrapolating data whenever possible. For, when age is unknown at a particular visit, it is extrapolated from the previous visit. If a subject has any missing critical information that cannot be estimated by reliable means, then the subject is removed from the assessment. Otherwise, the population means segregated by age and gender were used to replace the parameters, as shown in Appendix 4.
Framingham risk score takes the age (30-79), total cholesterol (mg/dL), HDL (mg/dL), systolic blood pressure (mmHg), and smoking status as input for the CVD risk model. This model is race-specific and is defined for non-Hispanic whites and African Americans. However, the study recommends using the risk model developed for non-Hispanic whites for an estimation of risk in populations other than African Americans and non-Hispanic whites.
The ASSIGN CVD score uses age 30-74, sex, family history of CHD/stroke, diabetes status, cigarette smoking status, systolic blood pressure (100-200 mmHg, extrapolated if used beyond this range), total cholesterol, HDL, and a derived social deprivation factor called SIMD. For the local Scottish population, rheumatoid arthritis is also a component. However, the score has been built without an arthritis element for outsiders, and we make use of that score. In our study data, the social deprivation factor is not available, and hence, a suggested score of 20 (middle of the most deprived fifths of the population) is used in place. The provisional values for unknown components are provided by the ASSIGN study and outlined in Appendix 3.
The ASCVD score based on ACC/AHA uses age (40-79), diabetes status, sex, race (African-American and Non-Hispanic White), smoking status, total cholesterol (mg/dL), HDL cholesterol (mg/dL), systolic blood pressure (mmHg) and treatment for hypertension as predictors. ASCVD equations are sex- and race-specific equations. They should be used for non-Hispanic whites and African Americans. However, the study recommends that equations for non-Hispanic whites may be considered for an estimation of risk in patients from populations other than African Americans and non-Hispanic whites.
The European SCORE model uses age, gender, systolic blood pressure (mmHg), total cholesterol (mmol/L), and smoking status as input variables. Subjects with missing data for these predictors are removed.
We implemented each model in a computer program based on published algorithms, and 100 incident CVD and 100 non-incident CVD subjects from MESA were selected for testing. To be sure that our simulation accurately reflected real-world clinical applications, the same MESA data were also tested on the original models available on the web and results were compared to our implemented model.
Statistical analyses
To compare the various models, we used 933 subjects with incident CVD and 5,785 subjects without any incident CVD. We computed the results with measures such as the area under the curve (AUC or C-statistic), sensitivity, specificity, and accuracy to estimate the performance. First, we analyzed the AUC to assess the discriminatory capability of the risk scores to correctly differentiate between two subjects, one who will develop the condition within ten years and one who will not. Second, we assess the agreement between the risks predicted by the models and the observed outcomes in the study by measuring the sensitivity and specificity of the models.
Results
Implemented models compared to public web-based applications
The outcomes in each implementation of a given risk score achieved 100% correlation with the results of public web-based applications.
Discrimination
The models showed similar C-statistics or AUC at the 10-year prediction of the disease with little variation. ASCVD showed slightly better discriminative ability with an AUC of 0.717 and SCORE showed the least (AUC 0.677) although the difference is not very big. Figure 1 shows the receiver operating characteristics of the four models and the associated areas under curve (AUC or C-statistics).
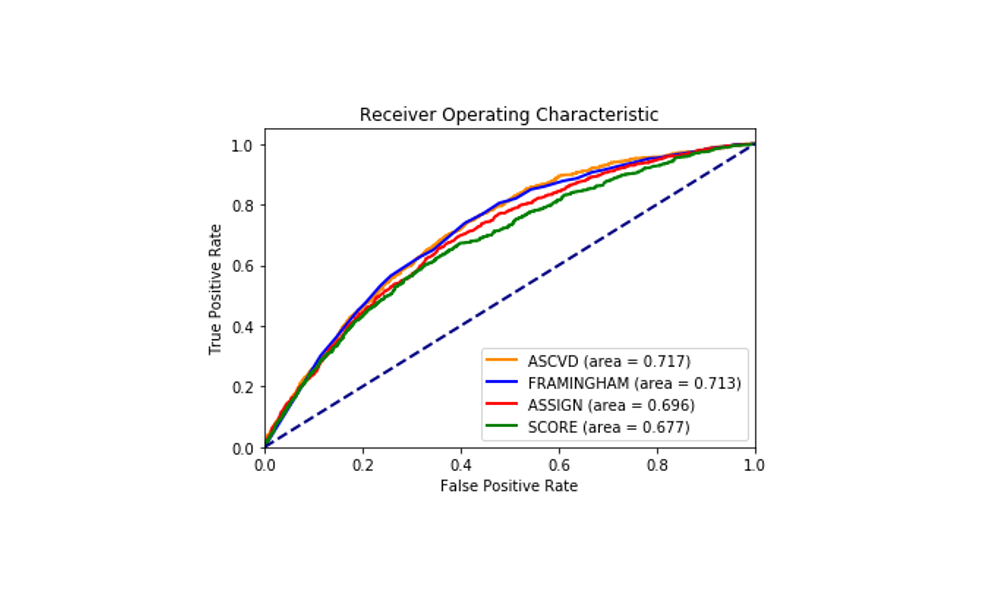
Figure 1. Receiver Operating Characteristics of the four models - ASCVD, Framingham, ASSIGN, and SCORE - on the MESA study data.
Calibration
Figure 2 shows the calibration plots on each of the risk scores. The calibration curve is very helpful in evaluating a model's performance and reliability in each population, especially when the score is developed on another population. These curves are obtained by plotting actual probabilities vs. predicted probabilities. Figure 2 depicts the calibration curve where the x-axis represents the predicted probabilities in 8 divided groups (also called bins that equal range of probabilities) are plotted against the y-axis which contains true probabilities of each of the groups. The true probabilities are obtained by taking the fraction of positives (CVD cases) in the respective groups. For example, if a group has a total of 10 subjects and 2 of them are CVD cases and the other 8 are non-CVD cases, then the true probability for that group is 20% (or 0.2). For an ideal model, this probability is a non-decreasing quantity matching the predicted probabilities (along the x-axis) represented by the black straight line with slope one starting at the origin of the graph.
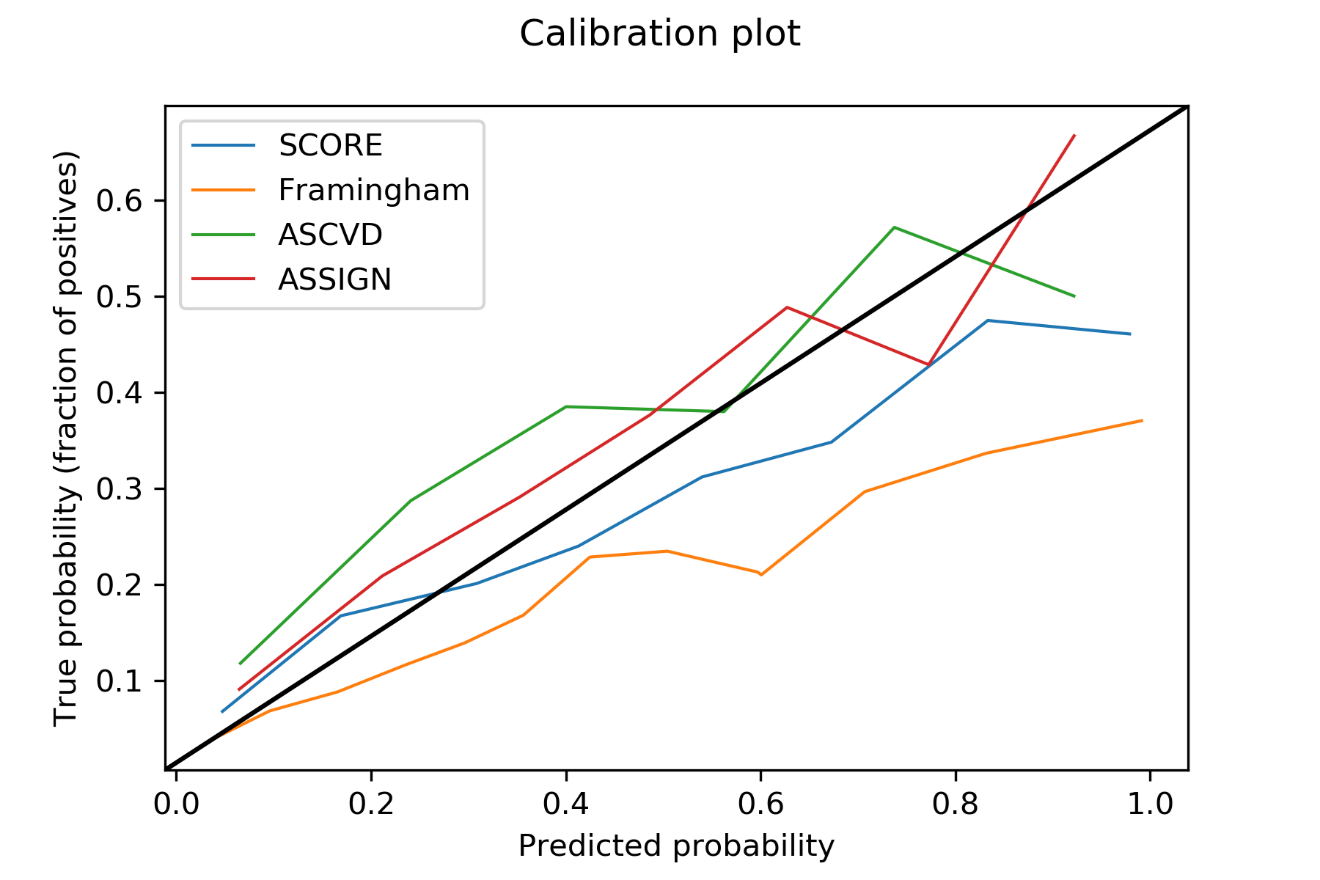
Figure 2. Calibration plots for the four cardiovascular disease risk scores showing true probabilities vs. predicted probabilities.
The four calibration curves for the four prediction models are shown in Figure 2 drawn in a different color for different models. From the curve for the Framingham score, we can see that as true probabilities increase, the predicted probabilities increase disproportionately. This shows that the Framingham score overestimates the CVD risk in the MESA population. This is also the same in SCORE, whose predicted probabilities are higher than true probabilities, but slightly better than Framingham, by being closer to the ideal calibration curve. On the other hand, ASCVD and ASSIGN scores are in closer agreement with the ideal calibration curve (the black line), and hence, the performance is better for the two scores in this population.
The models are also assessed by computing the sensitivity and specificity by taking the “high-risk” categories in each of the four models. We use a threshold value of the top 20% (predicted probability risk) to evaluate the calibration of the models. Table 3 shows an example of the discrimination capabilities of the models within the different sensitivities and specificities for this threshold. At this cut-off, the Framingham model shows a high sensitivity of 69.67% but with a low specificity of 62.21%. The ASCVD model shows a sensitivity of 46.73% and a specificity of 79.69%. These results contrast with the European models' SCORE and ASSIGN, which show relatively low sensitivities of 43.19% and 34.94%, but with higher specificities of 80.07% and 85.12%, respectively, for the said threshold. We note that the results will vary for different percentages of the threshold. The strict comparison can be depicted in Figure 2.
|
Sensitivity (95% CI) |
Specificity (95% CI) |
Accuracy (95% CI) |
||||
|
FRAMINGHAM |
69.67% |
66.61% to 72.61% |
62.21% |
60.95% to 63.46% |
63.93% |
61.96% to 66.01% |
|
ASCVD |
46.73% |
43.49% to 49.99% |
79.69% |
78.63% to 80.72% |
71.82% |
70.21% to 72.55% |
|
SCORE |
43.19% |
39.99% to 46.44% |
80.07% |
79.02% to 81.09% |
68.09% |
67.16% to 69.50% |
|
ASSIGN |
34.94% |
31.88% to 38.10% |
85.12% |
84.17% to 86.02% |
67.15% |
66.04% to 68.77% |
Conclusions
In this study, we have shown the performance of various cardiovascular risk scores in a multi-ethnic dataset. This validation study showed that the performance of four models for predicting CVD in a multi-ethnic population was nearly identical to each other. We observed that the high-risk candidates from one prediction model could easily be left out in another prediction model. This also shows that no model could precisely and accurately predict the absolute risk of cardiovascular diseases.
The discriminative abilities of the models varied minimally. Calibration problems can be mitigated by moving the thresholds, although this may lead to over-treatment in the case of identification of too many cases or under-treatment in case of too few cases identified. Compared to the Framingham model, all other models show poor calibration and need to be updated if it is used for the demographic represented by MESA study participants.
Our study found that the transportability of the predicted risks was generally poor from European scores to the American population. With the highest AUC and a good calibration curve compared to the other scores, ASCVD, which is based on the recommendation of the American Heart Association performs the best in our calibration experiments.
References
2. Thomas H, Diamond J, Vieco A, Chaudhuri S, Shinnar E, Cromer S, et al. Global Atlas of Cardiovascular Disease 2000-2016: The Path to Prevention and Control. Glob Heart. 2018 Sep;13(3):143-63.
3. Timmis A, Vardas P, Townsend N, Torbica A, Katus H, De Smedt D, et al. European Society of Cardiology: cardiovascular disease statistics 2021. Eur Heart J. 2022 Feb 22;43(8):716-99.
4. Joseph P, Leong D, McKee M, Anand SS, Schwalm JD, Teo K, et al. Reducing the Global Burden of Cardiovascular Disease, Part 1: The Epidemiology and Risk Factors. Circ Res. 2017 Sep 1;121(6):677-94.
5. Leong DP, Joseph PG, McKee M, Anand SS, Teo KK, Schwalm JD, et al. Reducing the Global Burden of Cardiovascular Disease, Part 2: Prevention and Treatment of Cardiovascular Disease. Circ Res. 2017 Sep 1;121(6):695-710.
6. Roth GA, Mensah GA, Johnson CO, Addolorato G, Ammirati E, Baddour LM, et al. Global Burden of Cardiovascular Diseases and Risk Factors, 1990-2019: Update From the GBD 2019 Study. J Am Coll Cardiol. 2020 Dec 22;76(25):2982-3021.
7. Damen JA, Hooft L, Schuit E, Debray TP, Collins GS, Tzoulaki I, et al. Prediction models for cardiovascular disease risk in the general population: systematic review. BMJ. 2016 May 16;353:i2416.
8. Pylypchuk R, Wells S, Kerr A, Poppe K, Riddell T, Harwood M, et al. Cardiovascular disease risk prediction equations in 400,000 primary care patients in New Zealand: a derivation and validation study. Lancet. 2018 May 12;391(10133):1897-907.
9. Alaa AM, Bolton T, Di Angelantonio E, Rudd JHF, van der Schaar M. Cardiovascular disease risk prediction using automated machine learning: A prospective study of 423,604 UK Biobank participants. PLoS One. 2019 May 15;14(5):e0213653.
10. Schnabel RB, Sullivan LM, Levy D, Pencina MJ, Massaro JM, D'Agostino RB Sr, et al. Development of a risk score for atrial fibrillation (Framingham Heart Study): a community-based cohort study. Lancet. 2009 Feb 28;373(9665):739-45.
11. Assmann G, Cullen P, Schulte H. Simple scoring scheme for calculating the risk of acute coronary events based on the 10-year follow-up of the prospective cardiovascular Münster (PROCAM) study. Circulation. 2002 Jan 22;105(3):310-5.
12. Tunstall-Pedoe H. The Dundee coronary risk-disk for management of change in risk factors. BMJ. 1991 Sep 28;303(6805):744-7
13. British-study, "British Regional Heart Study (BRHS)," https://www.ucl.ac.uk/iehc/research/primary-care-and-population-health/research/brhs/study-design.
14. Walker M, Whincup PH, Shaper AG. The British Regional Heart Study 1975-2004. Int J Epidemiol. 2004 Dec;33(6):1185-92.
15. Jee SH, Jang Y, Oh DJ, Oh BH, Lee SH, Park SW, et al. A coronary heart disease prediction model: the Korean Heart Study. BMJ Open. 2014 May 21;4(5):e005025.
16. Barroso LC, Muro EC, Herrera ND, Ochoa GF, Hueros JI, Buitrago F. Performance of the Framingham and SCORE cardiovascular risk prediction functions in a non-diabetic population of a Spanish health care centre: a validation study. Scand J Prim Health Care. 2010 Dec;28(4):242-8.
17. Hippisley-Cox J, Coupland C, Brindle P. Development and validation of QRISK3 risk prediction algorithms to estimate future risk of cardiovascular disease: prospective cohort study. BMJ. 2017 May 23;357:j2099.
18. Tunstall-Pedoe H. Cardiovascular Risk and Risk Scores: ASSIGN, Framingham, QRISK and others: how to choose. Heart. 2011 Mar;97(6):442-4.
19. Cooney MT, Dudina AL, Graham IM. Value and limitations of existing scores for the assessment of cardiovascular risk: a review for clinicians. J Am Coll Cardiol. 2009 Sep 29;54(14):1209-27.
20. Rodondi N, Locatelli I, Aujesky D, Butler J, Vittinghoff E, Simonsick E, et al. Framingham risk score and alternatives for prediction of coronary heart disease in older adults. PloS one. 2012 Mar 28;7(3):e34287.
21. Siontis GC, Tzoulaki I, Siontis KC, Ioannidis JP. Comparisons of established risk prediction models for cardiovascular disease: systematic review. BMJ. 2012 May 24;344:e3318.
22. Dahagam CR, Goud A, D'Souza J, Dhaliwal N. A Comprehensive Review of Predictive Risk Models for Cardiovascular Disease. American College of Radiology. 2016. https://www.acc.org/latest-in-cardiology/articles/2016/08/03/13/47/a-comprehensive-review-of-predictive-risk-models-for-cardiovascular-disease. Last accessed on November 16, 2019.
23. Wessler BS, Lai Yh L, Kramer W, Cangelosi M, Raman G, Lutz JS, et al. Clinical Prediction Models for Cardiovascular Disease: Tufts Predictive Analytics and Comparative Effectiveness Clinical Prediction Model Database. Circ Cardiovasc Qual Outcomes. 2015 Jul;8(4):368-75.
24. Goff DC Jr, Lloyd-Jones DM, Bennett G, Coady S, D'Agostino RB, Gibbons R, et al. 2013 ACC/AHA guideline on the assessment of cardiovascular risk: a report of the American College of Cardiology/American Heart Association Task Force on Practice Guidelines. Circulation. 2014 Jun 24;129(25 Suppl 2):S49-73.
25. Dawber TR, Meadors GF, Moore FE. Epidemiological Approaches to Heart Disease: The Framingham Study. Joint Session of the Epidemiology, Health Officers, Medical Care, and Statistics in the Seventy-eighth Annual Meeting the American Public Health Association, St. Louis, Mo, 1950.
26. D’Agostino Sr RB, Vasan RS, Pencina MJ, Wolf PA, Cobain M, Massaro JM, et al. General cardiovascular risk profile for use in primary care: the Framingham Heart Study. Circulation. 2008 Feb 12;117(6):743-53.
27. Woodward M, Brindle P, Tunstall-Pedoe H; SIGN group on risk estimation. Adding social deprivation and family history to cardiovascular risk assessment: the ASSIGN score from the Scottish Heart Health Extended Cohort (SHHEC). Heart. 2007 Feb;93(2):172-6.
28. Tunstall-Pedoe H, Woodward M, Tavendale R, A'Brook R, McCluskey MK. Comparison of the prediction by 27 different factors of coronary heart disease and death in men and women of the Scottish Heart Health Study: cohort study. BMJ. 1997 Sep 20;315(7110):722-9.
29. Conroy RM, Pyörälä K, Fitzgerald AP, Sans S, Menotti A, De Backer G, et al. Estimation of ten-year risk of fatal cardiovascular disease in Europe: the SCORE project. Eur Heart J. 2003 Jun;24(11):987-1003.
30. The European Cardiovascular Disease Risk Assessment Model. https://www.escardio.org/Education/Practice-Tools/CVD-prevention-toolbox/SCORE-Risk-Charts. Last accessed on October 31, 2019.
31. Giannuzzi P, Wood DA, Saner H. European Guidelines on CVD Prevention in Clinical Practice. Eur Heart J. 2007;28:2375-414.
32. Bild DE, Bluemke DA, Burke GL, Detrano R, Diez Roux AV, Folsom AR, et al. Multi-Ethnic Study of Atherosclerosis: objectives and design. Am J Epidemiol. 2002 Nov 1;156(9):871-81.